根据李沐 stanford 课程第三章梳理。
# 神经网络
神经网络是由具有适应性的简单单元组成的广泛并行互连的网络。
- 手工提取特征(用人的知识进行) --> 神经网络来提取特征
- 神经网络(可能更懂机器学习)来提取,可能对后面的线性或 softmax 回归可能会更好一些。
用神经网络的好处在于,不用费心思去想,提取的数据特征是否会被模型喜欢,但是计算量和数量都比手工提取的数量级要大很多。
# 线性模型
学习一条直线来拟合数据,适用于一些线性关系。
使用均方误差(MSE)作为目标函数,使得预测值趋近于真实值,但是作为分类关心的是对应类别的置信度。
解决方法:
- 把预测的分数换成概率的形式(Softmax 函数)
- 衡量真实值概率与预测值概率的区别,用 Cross-Entropy 交叉熵。只关心真实类比的预测情况。
# 多层感知机
稠密层(全连接层或线性层)有可学习的参数 W,b,计算 y=Wx+b

- 线性回归可以看成是,有 1 个输出的全连接层
- softmax 回归可以看成是,有 m 个输出加上 softmax 操作子
加入非线性性:激活函数(如 sigmoid、relu 函数),这样做可以模拟各种非线性函数。
可调整的超参数:隐藏层的输出维度、隐藏层的个数。
# 卷积神经网络
为什么要用 CNN:用 MLP 训练 ImageNet (300*300 的图片有 1000 个类),MLP 有 1 个隐藏层,隐藏层的输出有 1 万(输入大概为 9 万输出是一千,随机取了个中间值 1 万),这样的话模型就有 10 亿个参数可供学习。 这样可学习的参数太多了。所以我们要用处理图片分类的先验信息:
- Translation invariance 平移不变性:需要识别的目标在一幅图的一个地方换到另一个地方,不会发生太多的变化
- locality 局部性:识别一个物体不需要看较远的像素
卷积核:k*k 的窗口,通常被训练用于识别图片的一个模式。
池化层(汇聚层):卷积层对输入的位置是比较敏感的,任何一个物体在输入中移动时,会导致它对应的输出也会移动。对位置移动的鲁棒性,提出了 pooling layer(池化层或汇聚层)【就是每一次去计算 k*k 窗口的元素的均值(平均汇聚)或最大值(最大汇聚)】
卷积神经网络就是一个神经网络,将卷积层堆起来,用卷积来抽取图片中的空间信息【不一定要做图片,可以做跟空间信息有关的东西,只要满足本地性和平移不变性】
神经网络的设计模式:更现代的 CNN,如 AlexNet,ResNet 等,考虑了不同结构化信息和关注的问题。
# 循环神经网络
Dense layer->Recurrent networks:
- MLP:预测分类(one-hot),由前一个词预测下一个词。但是没有办法很好的处理序列和时序信息。不能将前面的词相加,也不能改变输入的特征数量。
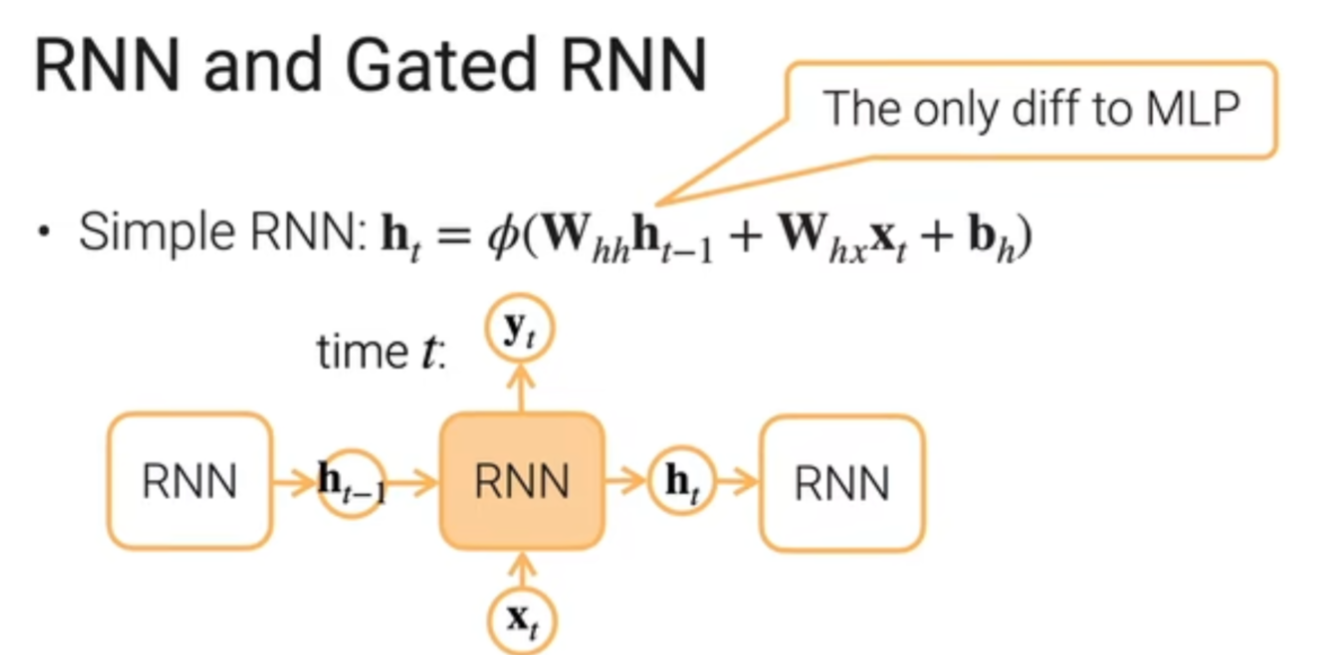
- RNN:将之前的信息(处理序列、时序信息)也传到这次的判断中。现代 RNN,对信息流有着更精细的控制,带有门。
- LSTM:在一些情况下抑制 Xt,比如遇到空格或者停用词的时候
- GRU:在一些情况下抑制 ht-1,比如需要忘记前序信息的时候
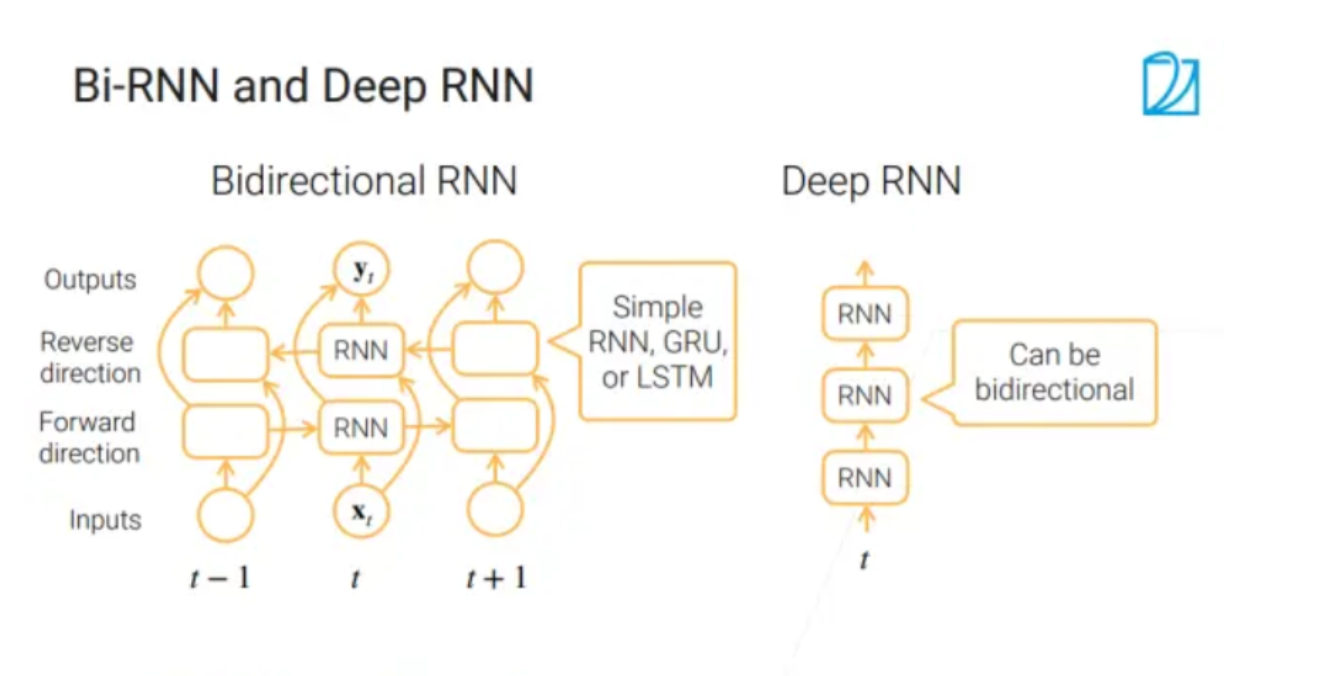
# Bi-RNN 和 Deep RNN
- 一个方向 --> 两个方向:正向层:将过去时刻的信息放入当前时刻,然后 反向层:时刻 t+1 的信息往时刻 t 的方向走【P.S. 这里的时刻我觉得不是时间的概念要看成是文本中的词序可能会好理解一点】,最后结合正向层和反向层的信息相结合作为 yt
- 把不同的层跟 MLP 一样累加起来,做成多层 RNN