# Lecture04.1 - 特殊树
考点
- 二叉搜索树考的概率比较低(?
- AVL 很可能考
- AVL 具体算法
- 证明不考
- 证明的结论要考:AVL 的复杂度
- m - 路搜索树不太考
- B 树经常考,B 树的复杂度指标和算法
- B 树算法不要求写代码、只需要知道代码流程、增删改查流程、复杂度记住
- AVL 树也有可能涉及代码
# 二叉搜索树 Binary Search Tree

Definition: A binary search tree is a binary tree that may be empty. A nonempty binary search tree satisfies the following properties:(二叉搜索树是一个可以为空的二叉树。一个非空的二叉树都满足如下性质)
- 每一个元素都含有一个关键字,并且每一个元素都有独一无二的关键字
- 一个树的左子树的关键字小于根中的关键字
- 一个树的右子树的关键字大于根中的关键字
- 根的左右子树还是二叉搜索树
它的左子树中所有项的值小于 X 中的值,它的右子树中所有项的值大于 X 中的值。

# 索引二叉树

索引二叉搜索树是通过将字段 leftSize 添加到每个树节点,从普通二叉搜索树派生而来的。
leftsize = 左子树大小 + 1
# 类代码

class BinaryNode { | |
BinaryNode( Comparable theElement ) { | |
this( theElement, null, null );// 调用本类中的其他构造方法 | |
} | |
BinaryNode( Comparable theElement, BinaryNode lt,BinaryNode rt ) { | |
element = theElement | |
left = lt; | |
right = rt; | |
} | |
Comparable element; | |
BinaryNode left; | |
BinaryNode right; | |
} |
# 方法定义



# 方法代码
# find

层层递归查找,按照左小右大
# findMin

// 使用递归查找结点 | |
private BinaryNode findMin( BinaryNode t ) { | |
if( t == null ) | |
return null; | |
else if( t.left == null ) | |
return t; | |
return findMin( t.left ); | |
} | |
// 迭代找最小结点 | |
private BinaryNode findMin(BinaryNode t){ | |
if(t != null){ | |
while(t.left != null){ | |
t = t.left; | |
} | |
} | |
return t; | |
} |
# findMax

// 递归找到最大结点 | |
private BinaryNode findMax( BinaryNode t){ | |
if(t == null){ | |
return null; | |
}else if(t.right == null){ | |
return t; | |
} | |
return findMax(t.right); | |
} | |
// 迭代找到最大结点 | |
private BinaryNode findMax( BinaryNode t ) { | |
if( t != null ) | |
while( t.right != null ) | |
t = t.right; | |
return t; | |
} |
# insertion


// 将数值插入固定位置的算法 | |
private BinaryNode insert( Comparable x, BinaryNode t ) { | |
// 先查找一次,如果找到了就不用进行查找 | |
if( t == null ) | |
t = new BinaryNode( x, null, null ); | |
else if( x.compareTo( t.element ) < 0 ) | |
t.left = insert( x, t.left ); | |
else if( x.compareTo( t.element ) > 0 ) | |
t.right = insert( x, t.right ); | |
else ;//duplicate; do nothing | |
return t; | |
} | |
//compareTo () 方法如果小于返回负数,大于返回正数 |
# 删除算法

- 如果结点本身不在树内,那么不需要删除
- 如果结点本身在树里面,删除需要分类
- 无子树:删除叶节点
- 一颗子树:直接连接
- 两颗子树:可以选择左子树的最大结点或者右子树的最小节点作为新结点

private BinaryNode remove( Comparable x, BinaryNode t ) { | |
//x 为需要删除的节点的值,t 为需要遍历的二叉搜索树 | |
if( t == null ) | |
return t; | |
if( x.compareTo( t.element ) < 0 ) | |
t.left = remove( x, t.left ); | |
else if( x.compareTo( t.element ) > 0 ) | |
t.right = remove( x, t.right ); | |
else if( t.left != null && t.right != null ) { | |
t.element = findMin( t.right ).element;// 把右树最小的复制给 t | |
t.right = remove( t.element , t.right );// 递归的删除 | |
}else{ | |
t = ( t.left != null ) ? t.left : t.right;// 一颗子树的情况 | |
} | |
} |
# 高度

二叉搜索树的高度会影响搜索,插入和删除算法的时间复杂度
最坏的情况:就是把一个有序的数列添加进入到空的二叉搜索树中去。时间复杂度为 O (n)

最好的情况:时间复杂度为 O (log2n)
# AVL Tree 自平衡的二叉搜索树

AVL 是人的名字
目的:AVL 树是一个用来增加二叉搜索树的平衡性并且减小平均搜索高度
AVL 的高度是 **O (log2n)** 的,所以对应的算法复杂度也是这样的。

# AVL 的定义

- 是二叉搜索树(左小右大)
- 左右子树的高度差不超过 1
- 注:树叶之间之差未必小于一,但是一个节点的左右子树的高度不能大于一
# 高度


AVL 树高从根节点到每一个叶节点之间的所有路径的最长的一条
x 节点 x 的平衡因子 = x 的右树的高度 - x 的左树的高度(可参考下图理解)

# 插入

# 情况 1:单旋转调整
外侧 —— 从不平衡结点沿刚才回溯的路径取直接下两层,如果三个节点处于一直线 ACE


考试会考如何构造 AVL 树
# 情况 2:双旋转调整
内侧 —— 从不平衡结点沿刚才回溯的路径取直接下两层,如果三个结点处于一折线 ACD

优先调整子树的平衡性

# 优先调整子树的平衡性


# 构建例子


单旋转:外侧 — 从不平衡结点沿刚才回溯的路径取直接下两层如果三个结点处于一直线 A,C,E
双旋转:内侧 — 从不平衡结点沿刚才回溯的路径取直接下两层如果三个结点处于一折线 A,C,D
# 代码实现

# insert


private AVLNode insert( Comparable x, AVLNode t ) { | |
if (t == null) | |
t = new AVLNode( x, null, null ); | |
else if ( x.compareTo(t.element) < 0 ){ | |
t.left = insert(x, t.left);// 不仅 x 插入左子树,而其左子树已经调平衡了,也就会子树已经旋转过了 | |
if(height(t.left) – height(t.right) == 2 ) | |
if(x.compareTo(t.left.element)<0) | |
// 根据大小进行调整 | |
t = rotateWithLeftChild (t);// 左子树的左子树,只要做一次左向单旋 | |
else t = doubleWithLeftChild(t);// 左子树的右子树,需要做一次左向双选 | |
// 下面是对称的插入在右子树上 | |
}else if(x.compareTo(t.element)>0) { | |
t.right = insert(x, t.right ); | |
if( height(t.right)–height(t.left)== 2) | |
if(x.compareTo(t.right.element)>0) | |
t = rotateWithRightChild(t); | |
else t = doubleWithRightChild(t) | |
}else; | |
t.height = max(height(t.left), height(t.right)) + 1; | |
return t; | |
} |
关键码为 x,需要插入的树根为 t
# rotateWithLeftChild

private static AVLNode rotateWithLeftChild( AVLNode k2 ) { | |
AVLNode k1 = k2.left;//k1 持有 k2 的左子树 | |
k2.left = k1.right;//k1 的右子树挂到 k2 的左子树上 | |
k1.right = k2;// 把 k2 自己挂到 k1 的右子树上 | |
k2.height = max(height(k2.left), height(k2.right)) + 1 ; | |
k1.height = max(height(k1.left), k2.height) + 1; | |
return k1; | |
} |
右下旋

右内侧
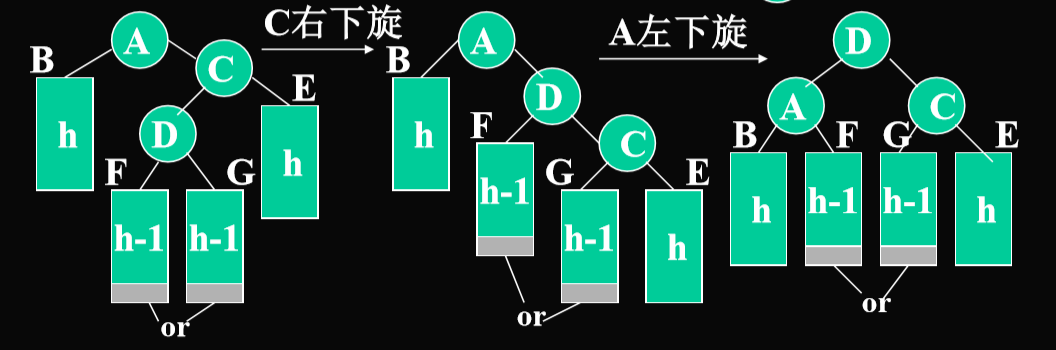
private static AVLNode doubleWithLeftChild( AVLNode k3 ) {
k3.left = rotateWithRightChild(k3.left);
return rotateWithLeftChild( k3 );
}

# AVL 树的删除

与二叉搜索树一样,但是会影响平衡


# 算法分析



# B 树
# m 叉搜索树

m-way 搜索树可能为空。如果是一个非空的树,则为满足以下属性的树:
- 在相应的扩展搜索树 (用外部节点替换零指针获得) 中,每个内部节点最多有 m 个子节点,在 1 到 m-1 个元素之间。
- 每个具有 p 元素的节点正好有 p+1 子节点。
- 假设任何节点都有 p 个元素,那么 C0 - Cp 是他们对应的 p+1 个子元素。
区分 element 和 children

- C0: The elements in the subtree with root c0 have keys smaller than k1 (在以 C0 为根的所有子树中的结点的值都小于 k1)
- Cp: Elements in the subtree with root cp have keys larger than kp (在以 Cp 为根的子树中的所有子树的值都大于 Kp)
- Ci: Elements in the subtree with root ci have keys larger than ki but smaller than ki+1, 1<=i<=p.
# 例子






# m 路搜索树的高度

一个高为 h 的 m 路搜索树最少有 h 个结点 (每一层只有一个结点),最多有 mh-1 个结点


n 个元素的 m 路搜索树,高度在 logm(n+1) and n
n: 2005-1 =32*1010-1

# 平衡的 m 路搜索树 ——B 树

- 树根至少要有两个分叉(树根至少有一个 key 值)
- 除了树根,其他结点至少要有 m/2 向上取值的分叉
- 外结点要在同一层


3 路 b 树的示例

# 性质

所有的外部结点都有相同的层数
外部结点的个数,是所有的 key 值个数加 1。

B 树的搜索算法和 m 叉搜索树的搜索算法是一样的。
算法分析:
- 对于高度为 h 的 B 树,访问磁盘的次数最多为 h 次
- T 是 m 阶高度为 h 的 B 树,在 T 中的结点个数为 n,每一次我们把一个结点读入内存。那么 n+1 个外部结点在第 h 层

高度为 h,key 值最少。【B 树每层有最少节点要求】
key 值最少为 2*(m/2)h-1 - 1, 小于此值到不了高度 h


# 插入

如果叶节点还没有满的时候,直接插入即可


如果叶节点已经满了的时候,会进行分类,将中间节点的一个值拉到上级结点 (这个结点在中间)。

插入到一个有 m 个子结点的节点中,比如 25 插入上面那个例子中,满了的节点会分裂成两个节点,就是把中间的提升,将剩下的裂开
一个新的指针会被添加指向满了的结点的父结点




如果插入操作会导致 s 个结点进行分裂,那么磁盘查找次数为
树高 h (在搜索路径上读,查找)+2s (写入 2s 次的分裂)+1 (有可能是创建新的结点,也可能是修改一个节点
h + 2s + 1
# 删除

- 将要被删除的元素的关键码的子节点是外部结点 [小正方形]
- 如果有超过 (m/2)(向上取整) 个关键码,直接删除
- 如果关键码个数不足 (m/2)(向上取整) 个,那么向邻居借关键码,如果够借,那么进行调整。如果不够借,那么合并邻居与此节点 (还要拉下来一个上级节点的关键码),这样子也可能会导致上级节点的关键码不足,如果根节点合并,则其高度被减少 1





- 要被删除的结点是一个非叶节点
- 删除这个节点
- 把这个节点替换成右子树中的最小关键码 (或者左子树中的最大关键码)
- 因为相当于删除了右子树的最小关键码 (或者左子树中的最大关键码),所以重复删除叶结点关键码的操作。



- S is the number of elements in the node (是节点的元素的个数)
- ei are the elements in ascending order of key (将元素按照键值升序排列)
- Ci are children pointers (子树结点)