publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
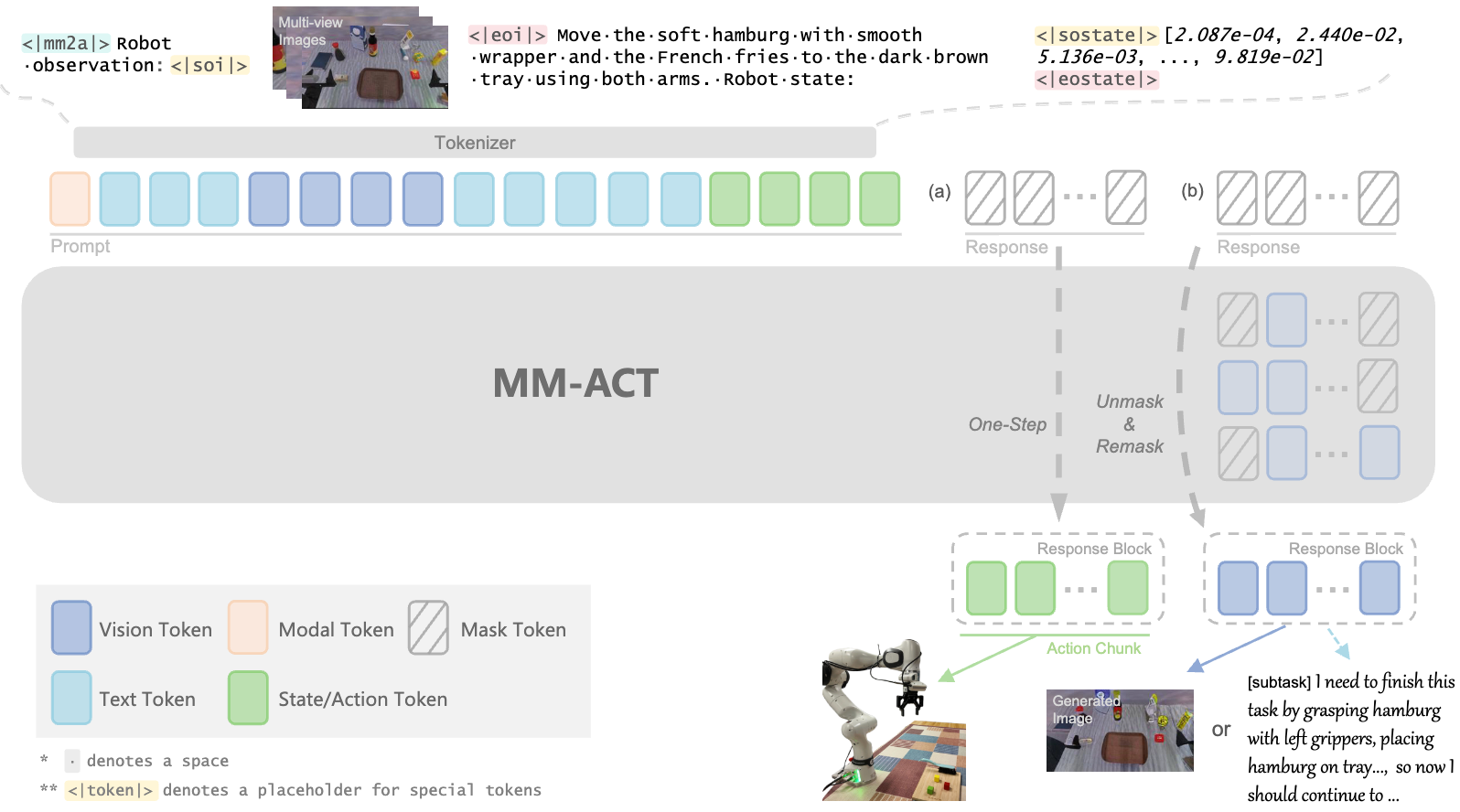
- MM-ACT: Learn from Multimodal Parallel Generation to ActHaotian Liang*, Xinyi Chen*, Bin Wang*, Mingkang Chen, and 11 more authors2025
A generalist robotic policy needs both semantic understanding for task planning and the ability to interact with the environment through predictive capabilities. To tackle this, we present MM-ACT, a unified Vision-Language-Action (VLA) model that integrates text, image, and action in shared token space and performs generation across all three modalities. MM-ACT adopts a re-mask parallel decoding strategy for text and image generation, and employs a one-step parallel decoding strategy for action generation to improve efficiency. We introduce Context-Shared Multimodal Learning, a unified training paradigm that supervises generation in all three modalities from a shared context, enhancing action generation through cross-modal learning. Experiments were conducted on the LIBERO simulation and Franka real-robot setups as well as RoboTwin2.0 to assess in-domain and out-of-domain performances respectively. Our approach achieves a success rate of 96.3% on LIBERO, 72.0% across three tasks of real Franka, and 52.38% across eight bimanual tasks of RoboTwin2.0 with an additional gain of 9.25% from cross-modal learning.
- AAAI 2026 (Oral)
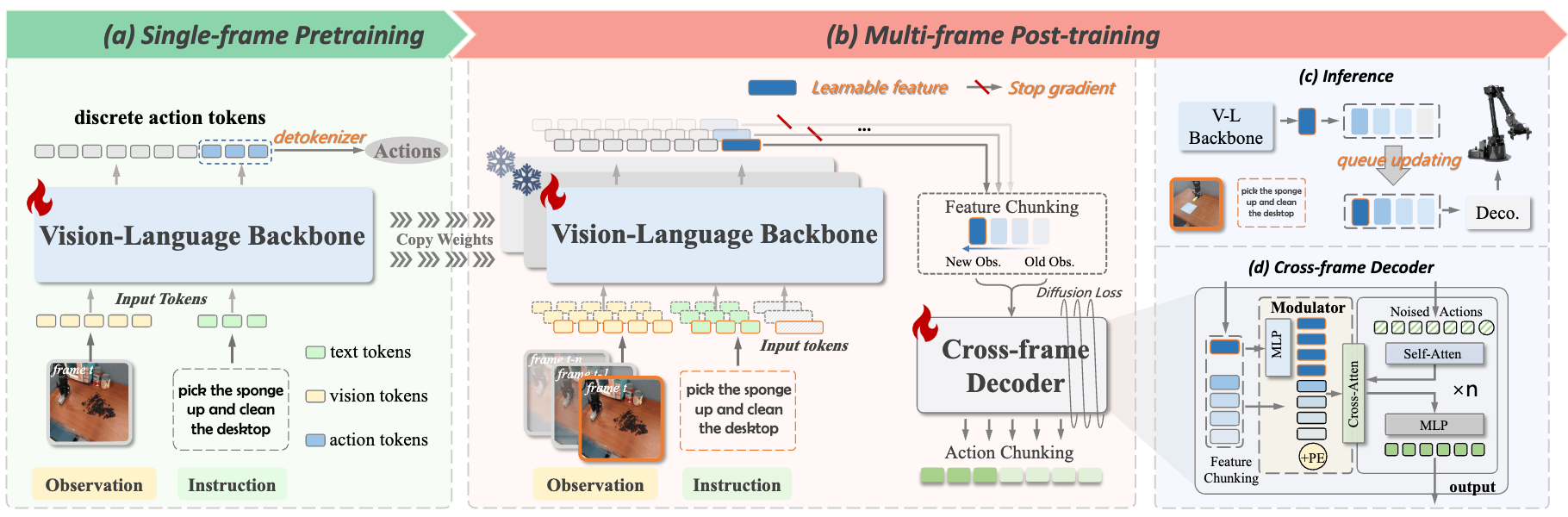 CronusVLA: Towards Efficient and Robust Manipulation via Multi-Frame Vision-Language-Action ModelingHao Li*, Shuai Yang*, Yilun Chen, Xinyi Chen, and 7 more authors2025
CronusVLA: Towards Efficient and Robust Manipulation via Multi-Frame Vision-Language-Action ModelingHao Li*, Shuai Yang*, Yilun Chen, Xinyi Chen, and 7 more authors2025Recent vision-language-action (VLA) models built on pretrained vision-language models (VLMs) have demonstrated strong performance in robotic manipulation. However, these models remain constrained by the single-frame image paradigm and fail to fully leverage the temporal information offered by multi-frame histories, as directly feeding multiple frames into VLM backbones incurs substantial computational overhead and inference latency. We propose CronusVLA, a unified framework that extends single-frame VLA models to the multi-frame paradigm. CronusVLA follows a two-stage process: (1) Single-frame pretraining on large-scale embodied datasets with autoregressive prediction of action tokens, establishing an effective embodied vision-language foundation; (2) Multi-frame post-training, which adapts the prediction of the vision-language backbone from discrete tokens to learnable features, and aggregates historical information via feature chunking. CronusVLA effectively addresses the existing challenges of multi-frame modeling while enhancing performance and observational robustness. To evaluate the robustness under temporal and spatial disturbances, we introduce SimplerEnv-OR, a novel benchmark featuring 24 types of observational disturbances and 120 severity levels. Experiments across three embodiments in simulated and real-world environments demonstrate that CronusVLA achieves leading performance and superior robustness, with a 70.9% success rate on SimplerEnv, a 26.8% improvement over OpenVLA on LIBERO, and the highest robustness score on SimplerEnv-OR. These results highlight the potential of efficient multi-frame adaptation in VLA models for more powerful and robust real-world deployment.
- arXiv 2025
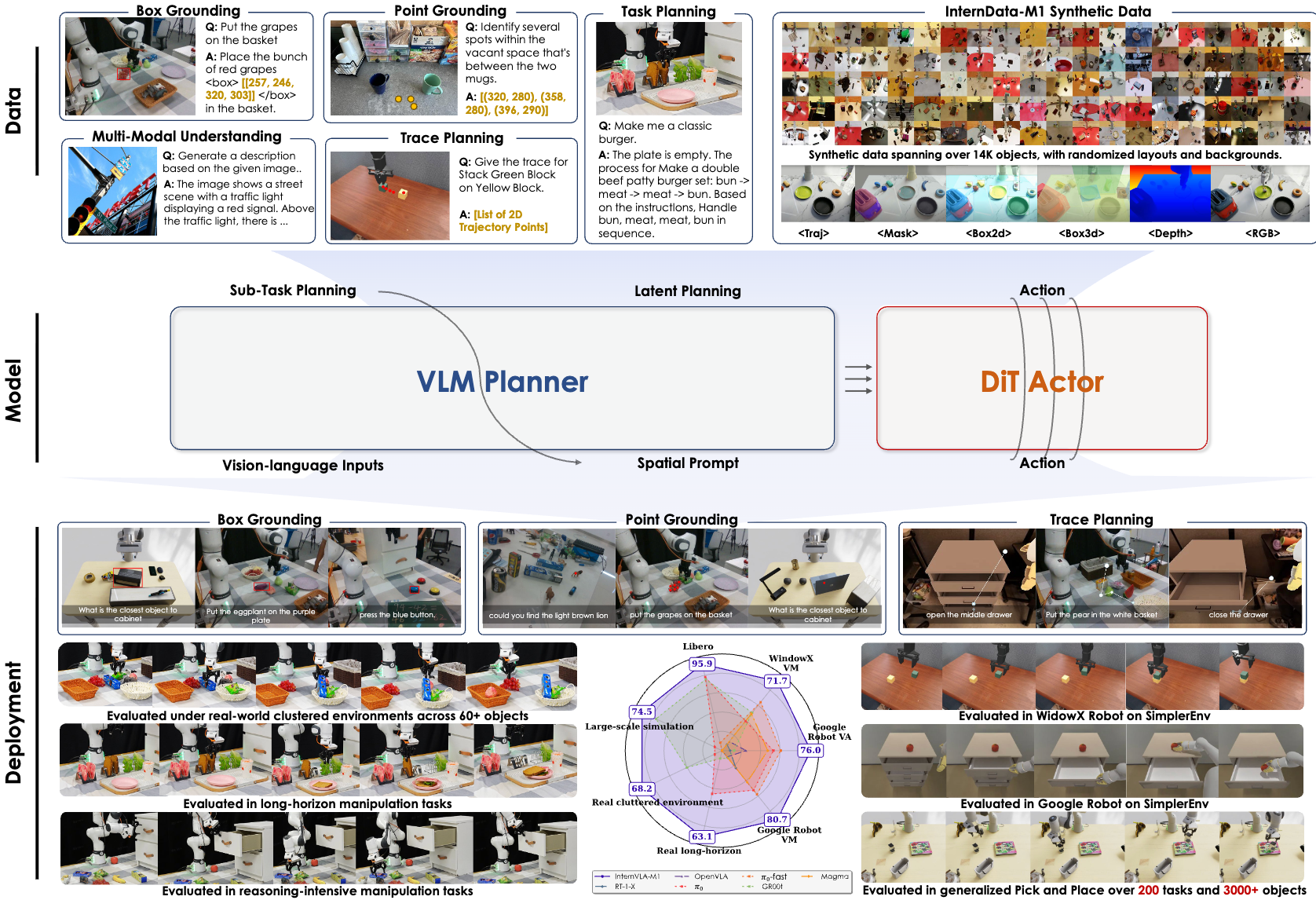 InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot PolicyXinyi Chen, Yilun Chen, Yanwei Fu, Ning Gao, and 25 more authors2025
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot PolicyXinyi Chen, Yilun Chen, Yanwei Fu, Ning Gao, and 25 more authors2025We introduce InternVLA-M1, a unified framework for spatial grounding and robot control that advances instruction-following robots toward scalable, general-purpose intelligence. Its core idea is spatially guided vision-language-action training, where spatial grounding serves as the critical link between instructions and robot actions. InternVLA-M1 employs a two-stage pipeline: (i) spatial grounding pre-training on over 2.3M spatial reasoning data to determine “where to act” by aligning instructions with visual, embodiment-agnostic positions, and (ii) spatially guided action post-training to decide “how to act” by generating embodiment-aware actions through plug-and-play spatial prompting. This spatially guided training recipe yields consistent gains: InternVLA-M1 outperforms its variant without spatial guidance by +14.6% on SimplerEnv Google Robot, +17% on WidowX, and +4.3% on LIBERO Franka, while demonstrating stronger spatial reasoning capability in box, point, and trace prediction. To further scale instruction following, we built a simulation engine to collect 244K generalizable pick-and-place episodes, enabling a 6.2% average improvement across 200 tasks and 3K+ objects. In real-world clustered pick-and-place, InternVLA-M1 improved by 7.3%, and with synthetic co-training, achieved +20.6% on unseen objects and novel configurations. Moreover, in long-horizon reasoning-intensive scenarios, it surpassed existing works by over 10%. These results highlight spatially guided training as a unifying principle for scalable and resilient generalist robots.
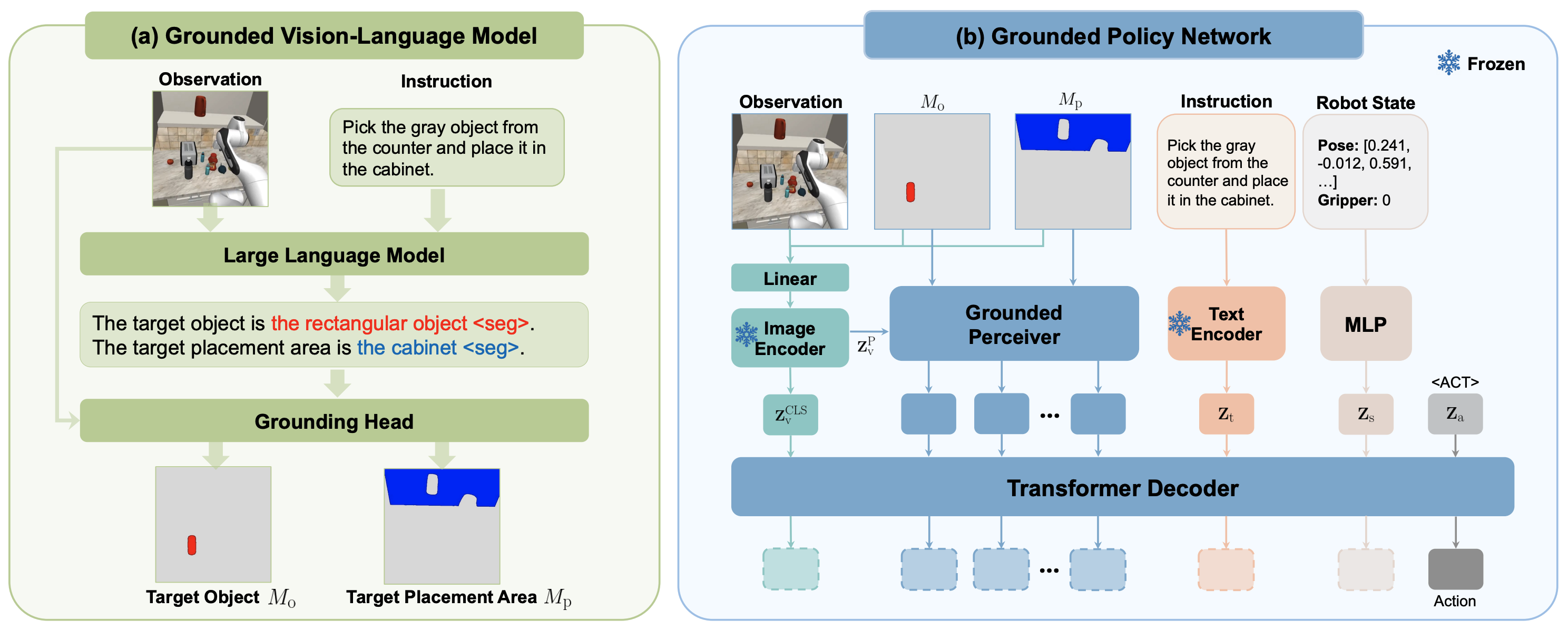
- RoboGround: Robotic Manipulation with Grounded Vision-Language PriorsHaifeng Huang*, Xinyi Chen*, Yilun Chen, Hao Li, and 5 more authorsIn Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), Jun 2025
Recent advancements in robotic manipulation have highlighted the potential of intermediate representations for improving policy generalization. In this work, we explore grounding masks as an effective intermediate representation, balancing two key advantages: (1) effective spatial guidance that specifies target objects and placement areas while also conveying information about object shape and size, and (2) broad generalization potential driven by large-scale vision-language models pretrained on diverse grounding datasets. We introduce RoboGround, a grounding-aware robotic manipulation system that leverages grounding masks as an intermediate representation to guide policy networks in object manipulation tasks. To further explore and enhance generalization, we propose an automated pipeline for generating large-scale, simulated data with a diverse set of objects and instructions. Extensive experiments show the value of our dataset and the effectiveness of grounding masks as intermediate guidance, significantly enhancing the generalization abilities of robot policies.
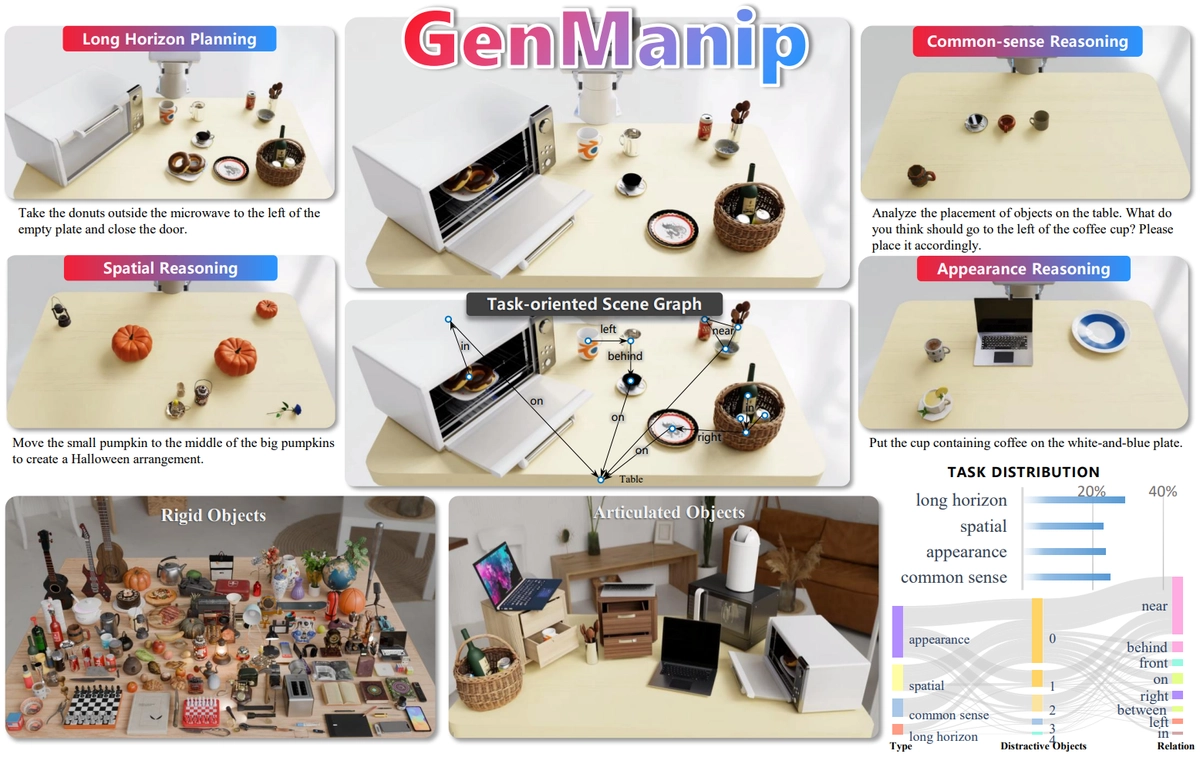
- GENMANIP: LLM-driven Simulation for Generalizable Instruction-Following ManipulationNing Gao*, Yilun Chen*, Shuai Yang*, Xinyi Chen*, and 6 more authorsIn Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), Jun 2025
Robotic manipulation in real-world settings remains challenging, especially regarding robust generalization. Existing simulation platforms lack sufficient support for exploring how policies adapt to varied instructions and scenarios. Thus, they lag behind the growing interest in instruction-following foundation models like LLMs, whose adaptability is crucial yet remains underexplored in fair comparisons. To bridge this gap, we introduce GenManip, a realistic tabletop simulation platform tailored for policy generalization studies. It features an automatic pipeline via LLM-driven task-oriented scene graph to synthesize large-scale, diverse tasks using 10K annotated 3D object assets. To systematically assess generalization, we present GenManip-Bench, a benchmark of 200 scenarios refined via human-in-the-loop corrections. We evaluate two policy types: (1) modular manipulation systems integrating foundation models for perception, reasoning, and planning, and (2) end-to-end policies trained through scalable data collection. Results show that while data scaling benefits end-to-end methods, modular systems enhanced with foundation models generalize more effectively across diverse scenarios. We anticipate this platform to facilitate critical insights for advancing policy generalization in realistic conditions. All code will be made publicly available.